Final Fact Sheet
Over the course of three years in the V4Design research project many technical innovations were developed. This page concludes on the main achievements and novelties that were published within the V4Design project in the form of a final fact sheet.
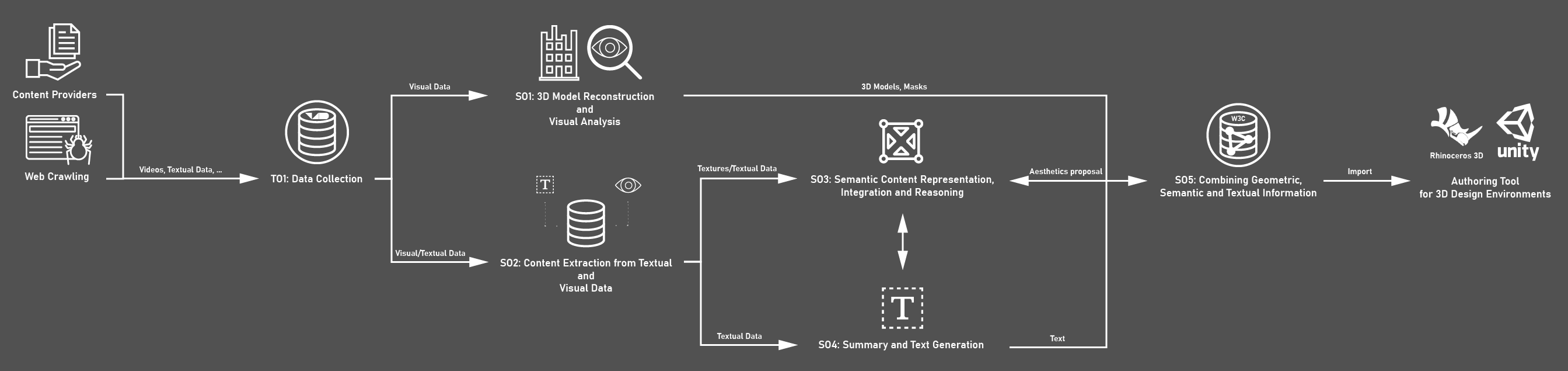
Nowadays large amounts of visual and textual data are generated, which are of great interest to architects and video game designers, such as archival footage, documentaries or movies. In their current form, it is difficult to be reused and repurposed for game creation, architecture, and design. To bridge this gap, V4Design develops technologies and tools that allow for automatic content analysis and seamless transformation to assist the creative industries in sharing content and maximize its exploitation. The conventional analogue prototype used by architects and video game designers include scale models and physical demo environments, such as rooms and apartments. V4Design helps to produce those prototypes faster and more cost efficient than the conventional methods. The differentiating factor for V4Design is the data collection and analysis processes, along with the sophisticated solutions for semantically representing, aggregating, and combining annotations coming from visual and textual analysis of digital content. The aim is to structure and link data in such a way to facilitate the systematic process, integration and organization of information and establish innovative value chains and end-user applications. Starting from the collection of visual and textual content (TO1) from content providers and online sources (web crawling), innovative design tools and workflows have been implemented that leverage visual and textual ICT technologies. More specifically, innovative 3D model reconstruction techniques are applied on the visual content (videos and images) to extract 3D assets of interest (SO1), such as buildings and objects. Computer vision and text analysis solutions further process the content to extract annotations (SO2) and dynamically enrich the generated 3D models with information, such as aesthetics, entities, BIM, categories, opinions from online reviews and critiques (SO3). At the end of the workflow, all the available information is semantically interlinked into rich knowledge graphs, offering advanced indexing and retrieval capabilities, while text generation is used to create multilingual summaries of the assets and assist end users in consuming the information (SO4). All information from multimodal components are interconnected following the semantic web format (RDF graphs) and interlinked with Linked Data using semantic queries, composing a rich Knowledge Base with intelligent retrieval capabilities (SO5). Finally, everything is embedded into common 3D Design Environments such as Rhinoceros 3D and Unity through the V4Design authoring tools V4D4Rhino and V4D4Unity. The whole development process was carefully reviewed and guided by our user partners based on pre-defined pilot use cases (PUCs) that represent real workflows (user requirements) of our target group. To learn more about the PUCs, please visit our “Showcase of the final results” webpage.
Innovations summary
Below you find a list that summarizes the key innovations and novelties archived in the V4Design project. The integration of all these innovations into the authoring tools was especially highlighted by the “European Commissions Innovation Radar” (https://v4design.eu/2021/02/02/v4design-on-european-commissions-innovation-radar/).
